Назад в прошлое
Первые операционные системы считывали пачки перфокарт и распечатывали результат на принтере. Такая организация вычислений называлась пакетным режимом. Чтобы получить результат, обычно приходилось ждать несколько часов. При таких условиях было трудно развивать программное обеспечение. [1]
В 1960-х годах компания IBM в рамках операционной системы OS/360 реализовала многозадачность, которая заключалась в разбиении памяти на несколько частей, называемых разделами, в каждом из которых выполнялось отдельное задание. Пример памяти многозадачной системы с различными заданиями изображен на рисунке 1. Пока одно задание ожидало завершения работы устройства ввода-вывода, другое могло использовать центральный процессор. Если в оперативной памяти содержалось достаточное количество заданий, центральный процессор мог быть загружен почти на все 100 % времени [2].

Хотя операционные системы третьего поколения неплохо справлялись с большинством научных вычислений и крупных коммерческих задач по обработке данных, но по своей сути они были все еще разновидностью систем пакетной обработки. В системах третьего поколения промежуток времени между передачей задания и возвращением результатов часто составлял несколько часов, так что единственная поставленная не в том месте запятая могла стать причиной сбоя при компиляции, и получалось, что программист полдня тратил впустую. Желание сократить время ожидания ответа привело к разработке режима разделения времени — варианту многозадачности, при котором у каждого пользователя есть свой диалоговый терминал. [2]
Процесс и поток
Основным понятием в любой операционной системе является процесс: абстракция, описывающая выполняющуюся программу. Процессы — это одна из самых старых и наиболее важных абстракций, присущих операционной системе. [2]
Процесс — это просто экземпляр выполняемой программы, включая текущие значения счетчика команд, регистров и переменных. [2]
Для реализации модели процессов операционная система ведет таблицу (состоящую из массива структур), называемую таблицей процессов, в которой каждая запись соответствует какому-нибудь процессу. (Ряд авторов называют эти записи блоками управления процессом — Process Control Block — PCB.) Эти записи содержат важную информацию о состоянии процесса, включая счетчик команд, указатель стека, распределение памяти, состояние открытых им файлов, его учетную и планировочную информацию и все остальное, касающееся процесса, что должно быть сохранено, когда процесс переключается из состояния выполнения в состояние готовности или блокировки, чтобы позже он мог возобновить выполнение, как будто никогда не останавливался. [2]
В традиционных операционных системах у каждого процесса есть адресное пространство и единственный поток управления. Фактически это почти что определение процесса. Тем не менее нередко возникают ситуации, когда неплохо было бы иметь в одном и том же адресном пространстве несколько потоков управления, выполняемых квазипараллельно, как будто они являются чуть ли не обособленными процессами (за исключением общего адресного пространства). В следующих разделах будут рассмотрены именно такие ситуации и их применение. [2]
Таненбаум называет выполнение процессов квазипараллельным в рамках одноядерных однопроцессных систем. Пример квазипараллельного выполнения изображен на рисунке 2.

Переключение процессора с выполнения одного процесса на выполнение другого называют переключением контекста. Стоит заметить, что время, затраченное на переключение контекста, не используется ОС для совершения полезной работы и является «накладными» расходами, снижающими производительность системы.
В любой многозадачной системе центральный процессор быстро переключается между процессами, предоставляя каждому из них десятки или сотни миллисекунд. При этом хотя в каждый конкретный момент времени центральный процессор работает только с одним процессом, в течение 1 секунды он может успеть поработать с несколькими из них, создавая иллюзию параллельной работы. Иногда в этом случае говорят о псевдопараллелизме в отличие от настоящего аппаратного параллелизма в многопроцессорных системах (у которых имеется не менее двух центральных процессоров, использующих одну и ту же физическую память). [2]
Выполнение задач на многоядерном процессоре обычно считается истинным параллелизмом. В отличие от псевдопараллелизма, который создаёт иллюзию параллельной работы на одноядерном процессоре за счёт быстрого переключения между задачами, многоядерные процессоры могут выполнять несколько задач одновременно, фактически используя разные ядра для разных потоков или процессов. Пример выполнения разных процессов на многопроцессорной системе представлен на рисунке 3.
За распределения процессорного времени отвечает планировщик ОС — компонент ядра, задача которого заключается в обеспечении максимально эффективного использования процессорных ресурсов и справедливого распределения вычислительной мощности.

Для простоты на рисунке 3 изображены два «абстрактных» одноядерных процессора (желтый и синий) и три «абстрактных» процесса, один из которых имеет два потока. На данном рисунке стоит обратить внимание, что один поток может выполняться на разных процессорах (в зависимости от решений планировщика). Можно заметить, что у третьего процесса могут возникать две возможные ситуации: оба потока выполняются параллельно на разных процессорах или выполняются квазипараллельно на одном.
Примечание: на рисунке 3 и далее два процессора можно заменить двумя ядрами одного процессора и на данном уровне абстракции рисунок не поменяется.
Достоинства потоков по сравнению с процессами:
- потоки сильно проще создавать и уничтожать по сравнению с более тяжеловесными процессами;
- единое адресное пространство памяти позволяет ускорить обмен данных избегая межпроцессного общения.
Применение многопоточности
Рассмотрим следующие подходы к использованию многопоточности:
- разделение вычислений и пользовательского интерфейса — выделяется отдельный поток для обработки пользовательских взаимодействий, в то время как другие потоки занимаются выполнением вычислений (позволяет повысить отзывчивость интерфейса независимо от нагрузки вычислений);
- асинхронные операции ввода-вывода: операции чтения/записи файлов, сетевого взаимодействия или обращений к базам данных выполняются в отдельных потоках (позволяет не блокировать основной поток в ожидании выполнения этих операций);
- параллельная обработка данных — разделение большого объема данных на части, которые будут обработаны параллельно;
- адаптивное распределение работы — задачи приложения являются простыми и распределяются между свободными потоками (пример: несколько работников, проверяющих брак на конвейере).
Данные подходы не являются абсолютными и могут образовывать гибриды, оптимально подходящие для конкретных задач приложения.
Стандартизация многопоточности
Институт инженеров электротехники и электроники (IEEE — Institute of Electrical and Electronics Engineers) в 1995 году определил стандарт IEEE standard 1003.1c — Portable Operating System Interface (POSIX), в рамках которого присутствовал пакет, касающийся потоков Pthreads. Данный стандарт поддерживается в большинстве UNIX-систем включая Linux и Mac OS. Использование pthreads в ОС семейства Windows требует использования библиотеки Pthreads-win32 или компилятора MinGW с флагом -lpthread. Подробно со стандартом можно ознакомиться в источнике [3]. Использование POSIX-threads будет рассмотрено в отдельной заметке.
Стандарт C++11 ввел в язык C++ стандартизированную поддержку многопоточности, включая потоки (threads), мьютексы (mutexes), условные переменные (condition variables) и атомарные операции. Это значительно упростило разработку многопоточных приложений на C++, делая код более переносимым между различными платформами. Библиотека Boost также содержит модули, описывающие работу с многопоточностью. Boost.Thread — часть библиотеки Boost, предлагает расширенные возможности для многопоточного программирования в C++.
В операционных системах семейства Windows существует набор интерфейсов WinAPI, который включает в себя инструменты для работы с потоками. Многопоточность стала доступна в рамках серверной версии Windows NT в 1993. С использовании потоков в WinAPI можно ознакомиться в источнике [4]. Так же в экосистеме .NET (включая C#, F# и VB.NET) многопоточность поддерживается через классы, находящиеся в пространстве имен System.Threading, предоставляя разнообразные возможности для создания и управления потоками, а также для синхронизации работы между ними.
Возможные проблемы в многопоточных приложениях
Многопоточные приложения, хотя и предлагают значительные преимущества в плане производительности и эффективности использования ресурсов, также связаны с рядом потенциальных проблем и сложностей, связанных с параллельным выполнением кода.
Многопоточные приложения требуют тщательного проектирования, чтобы избежать сложности управления состоянием и обеспечить эффективную работу с ресурсами. Неправильное проектирование может затруднить масштабирование и поддержку приложения.
Состояние гонки (Race condition)
Гонка данных возникает, когда два или более потоков одновременно пытаются изменить общие данные, и результат выполнения зависит от того, какой поток получит доступ первым. Это может привести к некорректному состоянию данных. Пример данной проблемы изображен на рисунке 4.
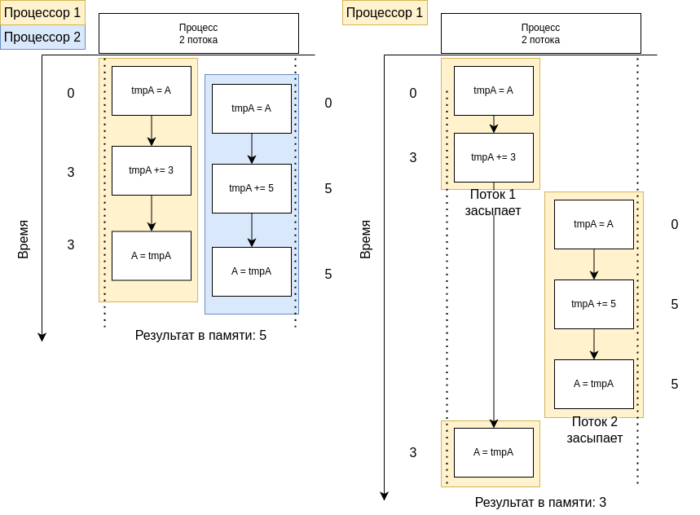
На рисунке 4 представлены две ситуации: состояние гонки на двухпроцессорной (слева) и однопроцессорной (справа) системах. Здесь указан простой высокоуровневый пример, но стоит учитывать, что проблема гонки на запись ресурсов может возникать даже с простыми операциями на уровне переноса данных из регистров процессоров: такая ситуация изображена на рисунке 5.
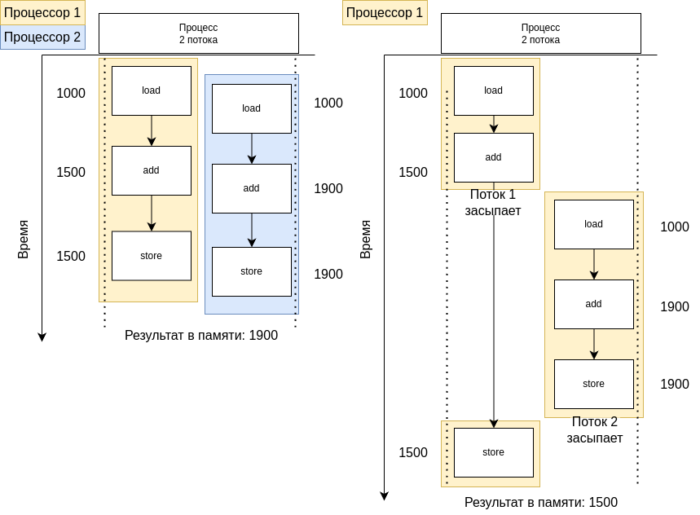
В качестве решения можно использовать механизмы блокировки, такие как мьютексы или семафоры, для обеспечения взаимоисключающего доступа к общим ресурсам.
В источнике [1] в рамках главы 6 имеется раздел о состоянии гонок.
Взаимная блокировка (Deadlock)
Взаимная блокировка возникает, когда два или более потоков ожидают друг друга для освобождения ресурсов, уже занятых ими, в результате чего все ожидающие потоки оказываются заблокированными и не могут продолжить выполнение. Проблема deadlock’a изображена на рисунке 6.
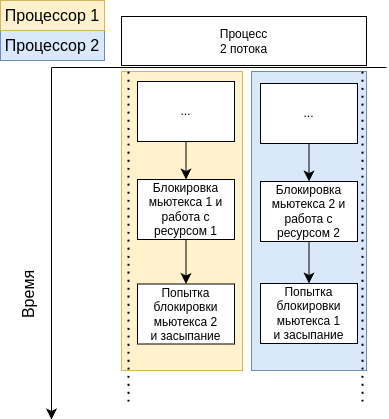
Для избежания таких ситуаций можно:
- применять иерархии блокировок, при которой все потоки захватывают блокировки в одном и том же порядке;
- использование тайм-аутов для блокировок;
- обнаружение и восстановление после взаимной блокировки.
В источнике [2] доступна большая глава 6 по взаимоблокировке.
Живые блокировки (Livelocks)
Живая блокировка возникает, когда два или более потоков активно реагируют на действия друг друга таким образом, что они продолжают изменять состояние без возможности продвижения вперёд. Причина зачастую кроется в реализации алгоритмов управления доступом к ресурсам или в ошибках в логике состояния приложения. Она может быть вызвана некорректным дизайном системы синхронизации, когда потоки постоянно пытаются избежать взаимной блокировки, активно меняя свои состояния, что приводит к бесконечному циклу.
Рассмотрим простой пример живой блокировки на примере задачи, где муж и жена пытаются поужинать, но между ними только одна ложка. Каждый из супругов вежлив и передает ложку, если другой еще не ел. Блок-схема и поведение потоков в случае живой блокировки изображены на рисунке 7.
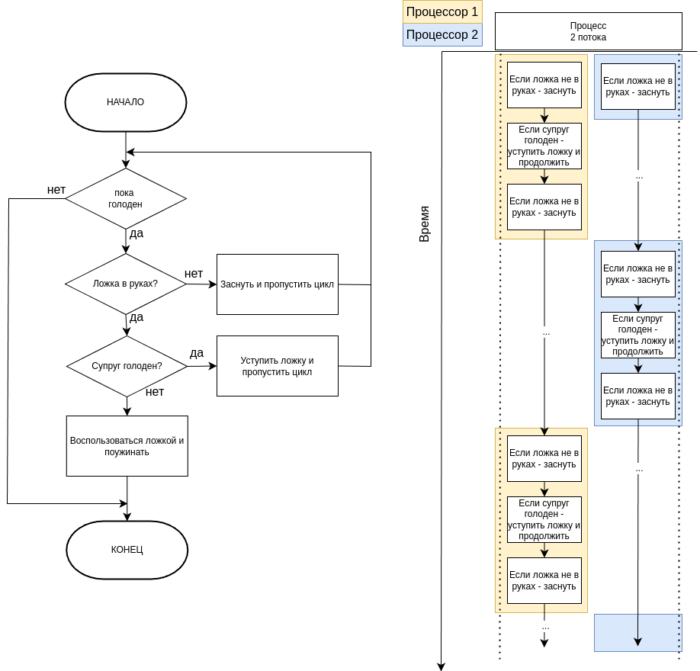
Важное замечание: если в задаче не отправлять поток в сон — будет максимальная нагрузка на процессор (ядро).
В источнике [2] в подразделе главы 6.7.3 описываются активные взаимоблокировки.
Голодание (Starvation)
Голодание происходит, когда один или несколько потоков не могут получить доступ к необходимым ресурсам в течение длительного времени из-за постоянного занятия этих ресурсов другими потоками.
Настройка приоритетов потоков позволяет выделять больше процессорного времени для «обделяемых» потоков.
Описание проблемы встречается в подразделе главы 2.5.1 источника [2] в контексте задачи обедающих философов.
Трудности отладки и тестирования
Многопоточные приложения сложнее отлаживать и тестировать, поскольку проблемы могут воспроизводиться нестабильно и зависеть от конкретной последовательности выполнения потоков, что затрудняет диагностику и устранение ошибок.
Инструменты синхронизации потоков
Инструменты синхронизации потоков необходимы для управления доступом к общим ресурсам в многопоточных приложениях и предотвращения проблем, связанных с конкурентным доступом, таких как состояния гонки, взаимные блокировки и другие.
Инструменты синхронизации потоков представлены рассматриваются Э. Таненбаумом в источниках [1] и [2]. Практическое использование POSIX-потоков и средств блокировок будет рассмотрено в следующей заметке.
Мьютексы (Mutexes)
Мьютексы предоставляют механизм блокировки, который позволяет потокам последовательно получать доступ к общему ресурсу. Когда поток захватывает мьютекс, другие потоки не могут получить доступ к защищенному им ресурсу до тех пор, пока первый поток не освободит мьютекс.
Семафоры (Semaphores)
Семафоры позволяют контролировать доступ к общим ресурсам, ограничивая количество потоков, которые могут одновременно использовать ресурс. Семафоры характеризуются счётчиком, который уменьшается, когда поток захватывает семафор, и увеличивается, когда поток освобождает его.
Условные переменные (Condition Variables)
Условные переменные используются для блокировки потока до наступления определённого условия. Они обычно используются в сочетании с мьютексами для ожидания изменения состояния приложения, при этом поток, ожидающий условия, не занимает ресурсы процессора.
Барьеры (Barriers)
Барьеры синхронизируют группу потоков в определённой точке программы. Все потоки должны достичь барьера, прежде чем любой из них сможет продолжить выполнение. Это полезно для координации фаз в параллельных алгоритмах.
Атомарные операции
Атомарные операции гарантируют, что комплексные операции (например, инкремент, декремент, сравнение и обмен) выполняются неделимо. Это позволяет потокам безопасно изменять общие данные без использования тяжеловесных механизмов блокировки.
Блокировка чтения-записи (RW-lock)
RW-lock (блокировка чтения-записи, блокировка «много читателей, один писатель») – это примитив синхронизации, который позволяет решить проблему «читателей-писателя». Проблема «много читателей, один писатель» довольно часто встречается при решении практических задач многопоточного программирования. Такая проблема появляется тогда, когда много потоков читают данные, и один поток пишет (изменяет) данные. Простой подход с использованием мьютекса считается медленным, так как нет необходимости блокировать ресурс, когда его только читают. Pthreads решает эту проблему с помощью блокировки чтения-записи, которая обеспечивает множественный доступ потоков читателей, и эксклюзивный доступ потока писателя.
Список источников
- Таненбаум Э., Остин Т. Архитектура компьютера. 6-е изд. — СПб.: Питер, 2013. — 816 с
- Таненбаум Э., Бос Х. Современные операционные системы. 4-е изд. — СПб.: Питер, 2015. — 1120 с.
- IEEE 1003.1c-1995. Standard for Information Technology—Portable Operating System Interface (POSIX(TM)) — System Application Program Interface (API) Amendment 2: Threads Extension (C Language). URL: https://standards.ieee.org/ieee/1003.1/7700/ (дата обращения 2024-03-23)
- Использование процессов и потоков — WinAPI32 apps. URL: https://learn.microsoft.com/ru-ru/windows/win32/procthread/using-processes-and-threads (дата обращения 2024-03-23)
